How to choose the best data storage solution for your MVP?
Today, solutions architects have many options when it comes to data storage. Deciding between relational and NoSQL technologies may seem easy, but the reality is far more complex. For instance, a brash choice of MongoDB over MySQL because it offers much more flexibility and functionalities – in addition to being more appealing to modern developers – may end up not serving business purposes.

Article Written by Remy Gendron, INGENO co-founder, author of the bestselling Software Development book From Impossible to DONE.
What are your needs?
Architects have a strong tendency to anticipate as much as they can, which in itself can be very desirable. However, trying to foresee all use cases and select technologies that cover all of these may not always bring the best results. Your requirements should be the guideline that dictates the storage strategy, of which four aspects are of critical importance:
The scope of your MVP may only require a simple data storage solution. Simplicity and the YAGNI principle reduce cost and time to market.
Post-MVP, new and unforeseen use cases may generate additional storage requirements for different data types.
As the business context changes, your data storage requirements evolve to address changing performance, scalability, compliance and security needs.
It is easier to evolve and optimize a modular storage strategy.
What are your criteria?
A wise architect should defer making technology choices for as long as possible. Until the need for new capabilities is evident, there may not be enough information to pick the best long-term option. An early mistake is more difficult and costly to fix than one made later in the project.
The following questions illustrate the complexity of addressing the data lifecycle post-MVP:
What use cases are prioritized over the next two years?
What deployment context (cloud vs on-prem) and geography regions are targeted?
What document, unstructured text, tabular, time series or graph data may we need to process besides core transactional information?
What are the future impacts of our initial data modeling architecture?
What trade-offs do we make between transactional atomicity and performance?
What is the ratio between read and write operations?
What type of analytics is planned, possibly including real-time, high-volume stream processing?
What modern features, such as data reactivity or offline client storage, are needed?
What data storage cost per user aligns with the business pricing model?
Vision for a data storage architecture
A solid digital platform data storage strategy relies on the following observations:
A digital product often needs to leverage many different storage types to optimize for different aspects of data processing such as atomicity, searchability, scalability, performance and cost.
At inception, an application's data-storing needs are simpler and highly transactional. ACID compliance greatly speeds up development.
Big Data best practices rely on a pipeline of information processing stages. Initially, data is kept in a somewhat plain data model. ETL asynchronous processes thereafter migrate the necessary data into optimized storages in downstream stages to better serve specific scenarios where different data models and technologies may be needed.
Assuming technologies of equal quality, maturity and adoption, your selection process for a specific data processing stage should address the following priorities in order:
Support the functional requirements of the next release.
Align with the available talent pool.
Minimize complexity to reduce cost and time to market.
Address operational concerns and non-functional SLAs (security, availability, scalability, performance).
These priorities highlight that a business-centric approach simplifies the evaluation of data storage options.
Why PostgreSQL?
At INGENO, most of our cloud projects use AWS Aurora for PostgreSQL as the initial data storage solution because:
Common to many applications, core business features profit from strong transactional integrity and known implementation patterns. Authentication, authorization, organizational management, parametrization, billing and auditing are commodities, and their implementation should face little design complications.
Relational data modeling and querying are fundamental skills mastered by most software developers.
Not needing knowledge of complex topics such as NoSQL data modeling, denormalization, eventual integrity, partitioning keys, transactional data islands, and more makes it easier to use less senior developers and reduces the need for costly configuration activities and code architectures.
Managed relational solutions such as AWS Aurora with 100% PostgreSQL compatibility make deploying and managing a highly secured data store much more accessible.
The availability and data security of AWS Aurora exceeds the highest industry standards while benefiting from scalability and performance qualities that rival those of many NoSQL databases.
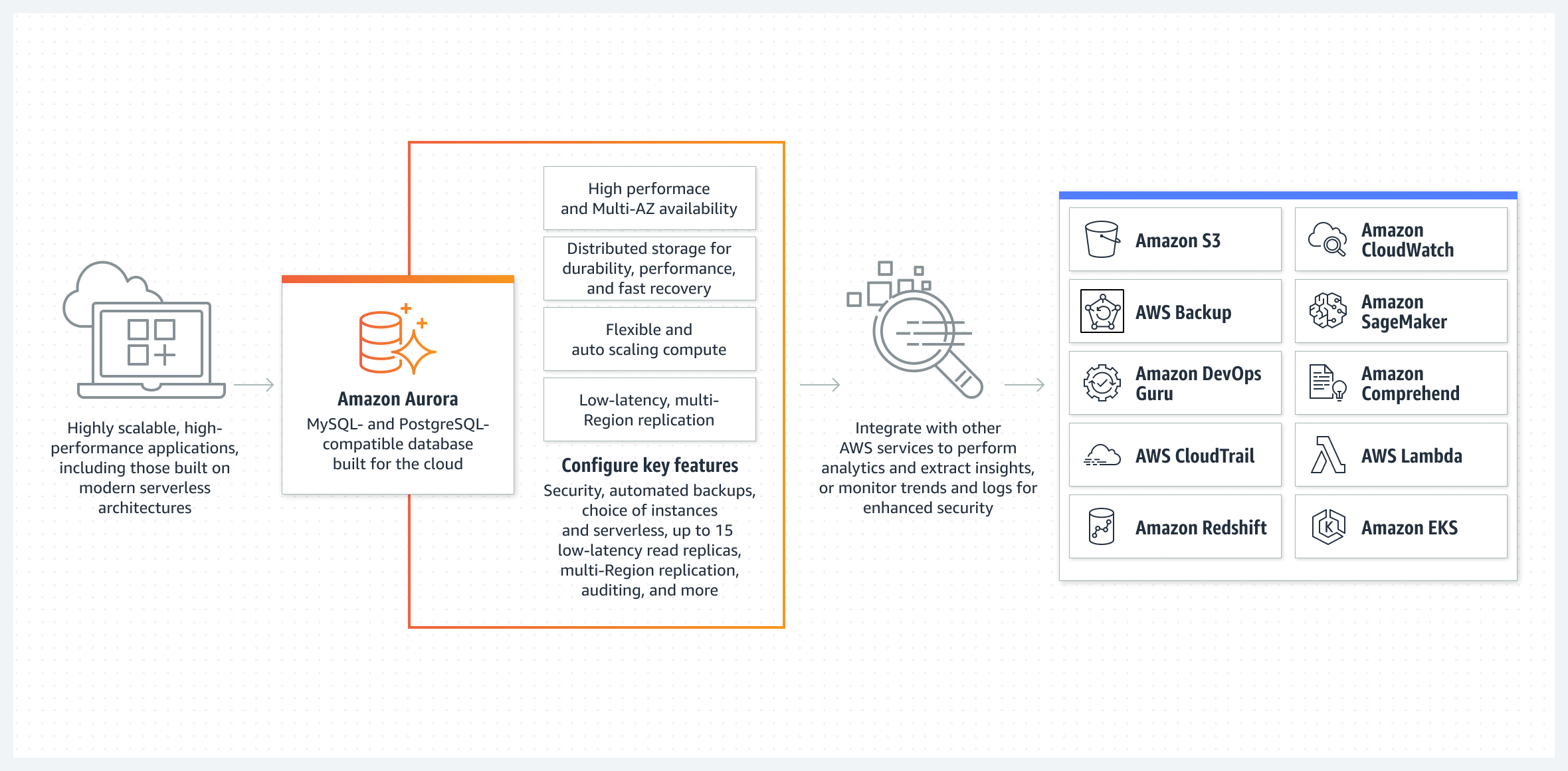
Amazon Aurora - How it works - © AWS
Aurora PostgreSQL also has many benefits over other proven relational solutions:
No licensing costs.
Native and optimized support for JSON data type, allowing for a hybrid storage of relational and NoSQL data.
Strong support for geospatial data.
NoOps storage auto-scaling.
Low latency read replicas with multi-region auto-scaling.
Multi-region data redundancy with automated backups.
Automated DevOps AI insights to discover and fix performance bottlenecks.
Textual search with performances approaching ElasticSearch for simple use cases.
Advanced modeling options like table inheritance.
Better performance than MySQL for complex workloads and queries.
Better concurrency than MSSQL for concurrent transactional and analytics queries.
Serverless compatibility.
Can be installed locally and natively on a MacOS development machine.
And many more cloud-optimized features.
PostgreSQL and MySQL are two products offering similar levels of features, quality and adoption. Even though we prefer PostgreSQL, anyone currently using MySQL will enjoy most of the benefits outlined above.
Conclusion
As a general storage solution for your application's initial MVP development, PostgreSQL covers most requirements. It also offers specialized features like full-text search that fills the gap until you require a dedicated, more scalable technology to complement your relational database.
As a managed service on Amazon AWS, Aurora PostgreSQL has better performance and scalability on equivalent hardware than native PostgreSQL while providing an improved operational experience.
Need advice for your MVP project? Strategy, design, software engineering: discover our services